|
Page d'accueil
Thèmes d'activités
<< Thème précédent
Thème suivant >>
Compression LZW: Lempel, Ziv, Welch
La
compression LZW est une
méthode non destructive
de compression de données, c'est à dire qu'il n'y aura
aucune perte lorsqu'on reconstituerales données initiales à partir des données
codées compressées.
Dans cette feuille de calcul, nous
compresserons puis décompresserons un texte défini à partir d'une chaîne de
caractères ou défini à partir d'un fichier texte.
L'unité élémentaire utilisée pour le
codage d'informations sera le bit
, ayant pour valeur 0 ou 1, chiffres de la numération
binaire (base
2). Un octet
(ou byte
en anglais) est une suite de 8
bits , représentable par
un entier de 0 à 255 en numération décimale
(base 10), ou par un entier de 0 à FF en numération
hexadécimale
(base 16).
LZW est l'une des meilleures
méthodes de compression actuelles. Etant protégée par un brevet, elle est peu
utilisée. Les compacteurs tels que ARJ ou Winzip, et certains formats tels que
le format d'images GIF utilisent la méthode LZ qui est moins performante mais
non protégée. La méthode LZW est cependant utilisée dans le monde Unix.
La méthode LZ, découverte en 1978 par
Lempel et Ziv, a profité d'améliorations successives pour aboutir en 1984 grâce
à Welch à l'algorithme de compression LZW.
La méthode LZW utilise un
dictionnaire
qui se construit de façon dynamique, au cours de la
compression mais aussi de la décompression. Ce dictionnaire n'est pas stocké
dans le fichier compressé. La compression s'effectue
en une seule lecture. La méthode étant basée sur les répétitions de caractères,
elle est surtout efficace sur des gros fichiers.
Principe de la méthode LZW
Pour économiser de la place, la
compression consiste à éviter les répétitions: un
dictionnaire contenant
toutes les répétitions est créé lors des deux opérations: compression et
décompression. Il doit être construit de la même manière et contenir les mêmes
informations.
Tous les ensembles de lettres qui sont lus
sont placés dans le dictionnaire, et sont numérotés. A chaque fois qu'un nouvel
ensemble est lu, on regarde dans le dictionnaire s'il existe déjà: si c'est le
cas, on émet son numéro vers le fichier compressé, sinon on le rajoute à la fin
du dictionnaire, et on écrit chacune des lettres dans le fichier compressé.
Les numéros des chaînes du dictionnaire
doivent dépasser 255, sinon il y aurait un risque de confusion avec les
caractères normaux dont le code Ascii
est inférieur ou égal à 255. Ici, nous choisirons des
numéros supérieurs ou égaux à 256 (variable
numero ) . Pour stocker ces nombres, les 8 bits
qui constituent un octet ne suffiront sans doute pas. Il faudra alors écrire des
nombres stockés sur 9, 10, 11,... bits. De façon générale, si les nombres utilisés
pour le dictionnaire sont codés sur n
bits, et que ces n
bits ne suffisent plus, il faudra passer à un codage sur
n +1 bits
(variable nb_bits
).
Pour que le décompresseur soit prévenu de ce changement, on émet un code de
contrôle ( ici on a choisi le code 0 ) vers le fichier compressé.
La procédure
convertir_binaire
( nb
, nb_bits
) convertit le nombre nb
en binaire sur nb_bits
, dans le sens des puissances croissantes
de 2.
|
> |
convertir_binaire:=proc(nb,nb_bits)
local c;
c:=convert(nb,base,2):
if nops(c)<nb_bits then return op(c),0$(nb_bits-nops(c)) else op(c) end if
end proc:
|
91 = 2^6 + 2^4 + 2^3 + 2^1 + 2^0:
|
> |
convertir_binaire(91,8); |
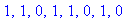
|
> |
convertir_binaire(0,9); |
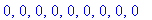
Compression
La procédure compression_LZW
( ch
:: string) compresse la chaîne de caractères
ch par la méthode LZW et
donne pour résultat la la chaîne de caractères
emis des bits émis via l'algorithme:
initialisation des variables
pour chaque caractère car de ch faire
si tampon+car est dans le dictionnaire
tampon = tampon+car
si nb_bits n'est plus suffisant
émettre le caractère de contrôle 0 sur nb_bits
nb_bits = nb_bits+1
fin si
sinon
émettre le code pour tampon
ajouter tampon+car dans le dictionnaire
tampon = car
fin si
fin faire
émettre le code pour tampon
|
> |
compression_LZW:=proc(ch::string)
local emission,nb_bits,tampon,numero,k,code,emis,dict,car,tmp;
emission:=proc(t::string)
if length(t)=1 then
emis:=cat(emis,convertir_binaire(Ord(t),nb_bits))
else emis:=cat(emis,convertir_binaire(code[t],nb_bits))
end if
end proc;
if ch="" then return "" end if;
emis:="": nb_bits:=8: tampon:=ch[1]: numero:=256: dict:=[]:
for k from 2 to length(ch) do
car:=ch[k]: tmp:=cat(tampon,car):
if member(tmp,dict) then
tampon:=tmp:
if code[tampon]>=2^nb_bits then
# émission d'un caractère de contrôle nul et augmentation du nombre
de bits
emis:=cat(emis,convertir_binaire(0,nb_bits)): nb_bits:=nb_bits+1:
end if
else
emission(tampon):
dict:=[op(dict),tmp]: code[tmp]:=numero:
numero:=numero+1: tampon:=car
end if;
end do;
emission(tampon);
emis
end proc:
|
|
> |
ch:="am
stram gram pic et pic et colégram": s:=compression_LZW(ch): |
La procédure
convertir
_ decimal
( s
:: string) convertit la chaîne de caractères
s de
bits en décimal:
|
> |
convertir_decimal:=proc(s::string)
local i,t,dec;
t:=NULL:
for i in s do
t:=t,parse(i)
end do:
t:=[t]:
dec:=convert(t,base,2,10);
sum(dec[k]*10^(k-1), k=1..nops(dec))
end proc:
|
|
> |
convertir_decimal("00011010"); |
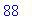
|
> |
convertir_decimal("111000001"); |
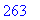
Décompression
La procédure decompression_LZW
( s
:: string) décompresse la chaîne de caractères
s de
bits en une chaîne de
caractères emis
par la méthode LZW via l'algorithme:
initialisation des variables
tant que l'on peut lire un nouvel ensemble de nb_bits faire
dec = code décimal de cet ensemble
si dec = 0
nb_bits = nb_bits+1
ajuster le code du numéro courant dans le dictionnaire à tampon+tmp[1]
sinon
tmp = caractères associés à dec
émettre tmp
tampon = tampon+tmp[1]
ajouter tampon dans le dictionnaire
tampon = tmp
fin si
fin faire
|
> |
decompression_LZW:=proc(s::string)
local nb_bits,pos,dec,tampon,numero,code,emis,tmp;
nb_bits:=8: pos:=1: emis:=Char(convertir_decimal(s[1..8])):
numero:=256: tampon:=emis:
while pos+nb_bits<=length(s) do
pos:=pos+nb_bits:
dec:=convertir_decimal(s[pos..pos+nb_bits-1]);
if dec=0 then # lecture du caractère de contrôle 0, augmentation du nombre
de bits
pos:=pos-1: nb_bits:=nb_bits+1:
code[numero]:=cat(tampon,tmp[1])
else
if dec<=255 then tmp:=Char(dec) else
if assigned(code[dec]) then tmp:=code[dec] end if
end if:
emis:=cat(emis,tmp):
tampon:=cat(tampon,tmp[1]):
code[numero]:=tampon: numero:=numero+1:
tampon:=tmp
end if;
end do;
emis
end proc:
|
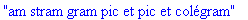
Lecture d'un fichier source:
La procédure
lire_fichier
lit un fichier texte défini par son nom:
|
> |
lire_fichier:=proc(nom::string)
local t,f,ligne,c;
t:="";
f:=FileTools[Text][Open](nom);
while not FileTools[AtEndOfFile](f) do
ligne := FileTools[Text][ReadLine](f);
t:=cat(t,ligne,"\n");
end do;
FileTools[Text][Close](f);
t;
end proc:
|
Exemple
On lit un texte de Rabelais à partir d'un fichier:
|
> |
texte_source:=lire_fichier("C:\\Documents and Settings\\Propriétaire\\Mes
documents\\Maple\\codage\\LZW\\Rabelais.txt");
|




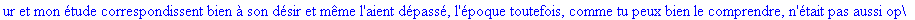


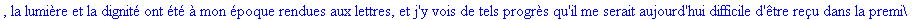


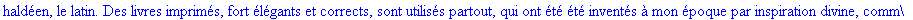


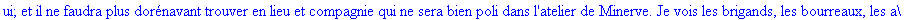
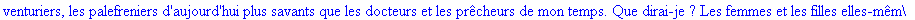
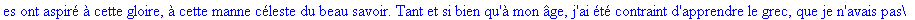

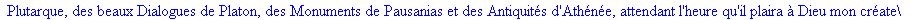





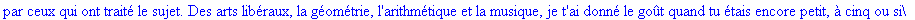

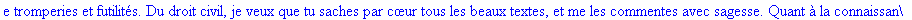

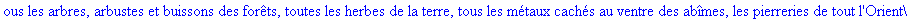
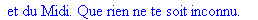

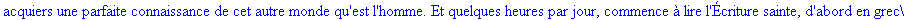
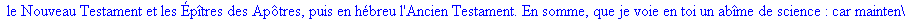
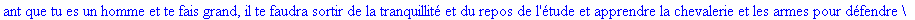
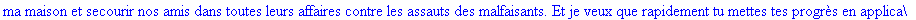


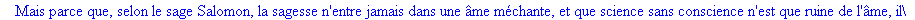
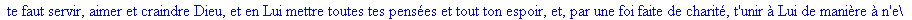
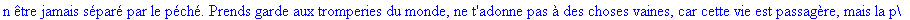


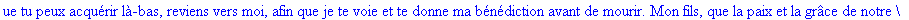



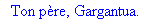



|
> |
temp:=compression_LZW(texte_source): |
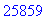
Le texte compressé pour cet exemple a donc
une taille de 25859 bits (contre 47056 bits pour le texte source), soit un taux
de compression de 45.05%..
|
> |
rho:=evalf(100*(1-length(temp)/(8*length(texte_source))),4):
print(`Taux de compression en %`=rho);
|

Comment stocker comme en mémoire
une chaîne de caractères binaires 0,1? C'est le travail effectué par la
procédure stocker
.
On code d'abord la longueur de la chaîne sur 2 octets (on suppose longueur <
65536 = 16^4 = 64Ko) :
exemple: si la chaine a une longueur 60004, soit en hexa EA64
EA (hex) = 234 (dec) 64 (hex) = 100 (dec) donc on code la longueur 234 100
Si on fait des "paquets" de 8 caractères (octets) , on peut coder chaque
"paquet" par un nombre entre 0 et 255.
Exemple:
"00001101" sera codé 2^3+2^2+2^0=13.
"10000000" sera codé 2^7=128.
Le pb est que la chaîne totale n'a pas toujours une longueur multiple de 8.
On regarde le reliquat, c'est à dire le reste modulo 8, on le code avec un
nombre comme précédemment.
Exemple:
Un reliquat "0001" sera codé: 1
Ainsi "00001101100000000001" sera codé 13 128 1
|
> |
stocker:=proc(s::string)
local h,j,k,n,q,r,t,L;
n:=length(s);
L:=iquo(n,256),irem(n,256):
q:=iquo(n,8): r:=irem(n,8):
for j to q do
h:=0: for k from 0 to 7 do h:=h+parse(s[8-k+(j-1)*8])*2^k end do:
L:=L,h
end do:
if r>0 then
t:=substring(s,q*8+1..q*8+r):
h:=0: for k from 0 to r-1 do h:=h+parse(t[r-k])*2^k end do:
L:=L,h
end if:
[L]
end proc:
|
La procédure
ecrire_fichier_compresse
stocke sous forme de liste la chaîne
temp (qui avait été
compressée par la méthode LZW) et écrit sur le disque le fichier défini par son
nom :
|
> |
ecrire_fichier_compresse:=proc(nom::string)
local bytes,nb,f;
global temp;
bytes:=stocker(temp):
f:=open(nom,WRITE):
nb:=nops(bytes):
print(cat(nb,` octets`));
writebytes(f,[iquo(nb,256),irem(nb,256)]):
writebytes(f,bytes):
close(f)
end proc:
|
|
> |
ecrire_fichier_compresse("C:\\Documents and Settings\\Propriétaire\\Mes
documents\\Maple\\codage\\LZW\\Rabelais CompLZW.txt",texte_source);
|
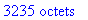
Pour cet exemple: au total 3235 octets
écrits.
La procédure
lire_fichier_compresse
lit sur le disque le fichier compressé défini par son
nom:
|
> |
lire_fichier_compresse:=proc(nom::string)
local f,nb,L,T;
f:=open(nom,READ);
L:=readbytes(f,2):
nb:=L[1]*256+L[2];
T:=readbytes(f,nb):
print(cat(nb,` octets`));
close(f):
T;
end proc:
|
|
> |
f:=lire_fichier_compresse("C:\\Documents and Settings\\Propriétaire\\Mes
documents\\Maple\\codage\\LZW\\Rabelais CompLZW.txt"): |
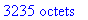
Pour cet exemple: lecture de 3235 octets.
La procédure reconstruit la chaîne de 0 et de 1 que l'on décompressera ensuite
pour restituer le texte-source original:
|
> |
reconstruire:=proc(s::list)
local n,q,r,i,j,k,t,L;
n:=s[1]*256+s[2]:
q:=iquo(n,8): r:=irem(n,8):
t:="":
for k from 1 to q do
if s[k+2]=0 then L:=[0] else L:=convert(s[k+2],base,2) end if:
j:=nops(L):
if j<8 then for i from 0 to 7-j do L:=[op(L),0] end do end if:
for i from nops(L) to 1 by -1 do t:=cat(t,L[i]) end do:
end do:
if r>0 then
if s[q+3]=0 then L:=[0] else L:=convert(s[q+3],base,2) end if:
j:=nops(L):
if j<r then for i from 0 to r-1-j do L:=[op(L),0] end do end if:
for i from nops(L) to 1 by -1 do t:=cat(t,L[i]) end do:
end if:
t
end proc:
|
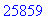
Décompression par la
méthode LZW:




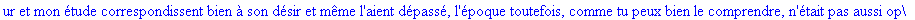


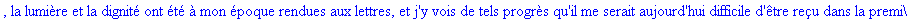


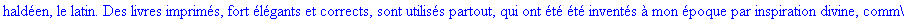


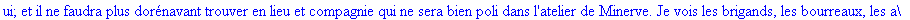







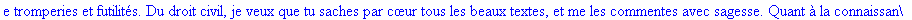

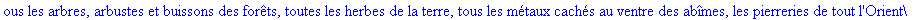
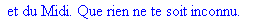

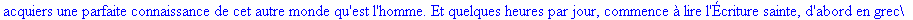
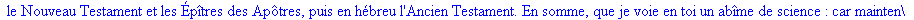
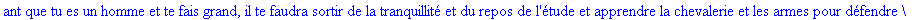
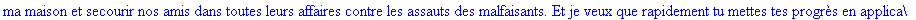


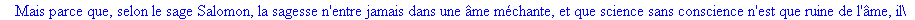
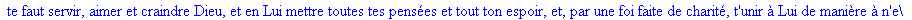
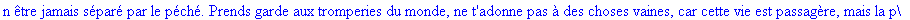


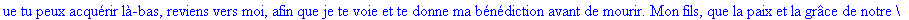





©
- Alain Le Stang - Navigation optimisée pour une résolution 1024 x 768.
|